自定义
使用agent模式纳管无独立公网IPV4地址的节点
对于一些本地设备,虽然具备 IPv4 公网访问能力,但由于没有固定或动态的独立 IPv4 地址,因此无法通过标准模式使用 SSH 直接纳管节点。针对这类场景,现提供一种新的纳管方式 —— Agent 模式。
新增节点时,点击对应的 Agent 模式 后,将进入基础信息配置页面。
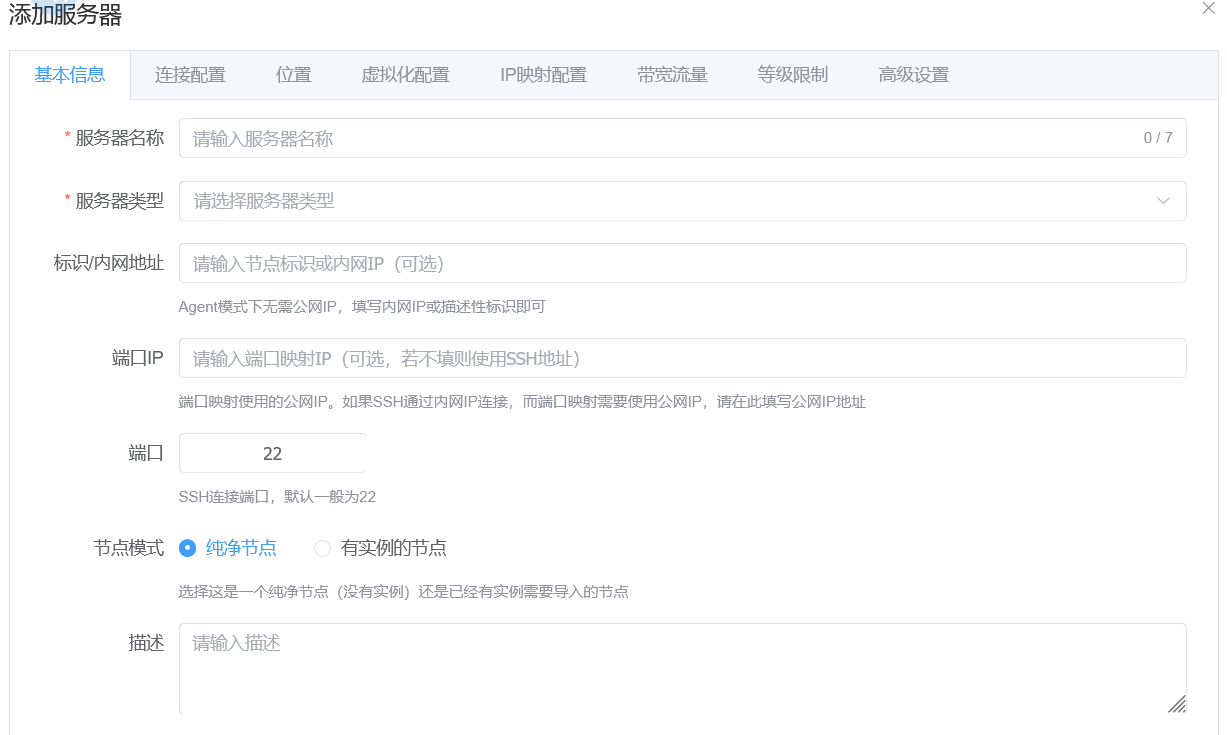
与常规的标准模式不同,Agent 模式下:
IP 地址端口
这两项不再为必填项,即使留空也可以正常纳管节点。
本地节点 / 家宽节点 / NAT 网络环境节点 不要填写 IP 地址和端口,保持留空即可。
云服务器 / 有固定 IPv4 的服务器 可以正常填写 IP 和端口。
需要注意的是:
若 IP 地址 与 端口 留空,则后续 网络模式 仅支持选择:无端口映射模式
若填写了 IP 与端口,则后续 网络模式 与标准模式一致,可选择全部类型。
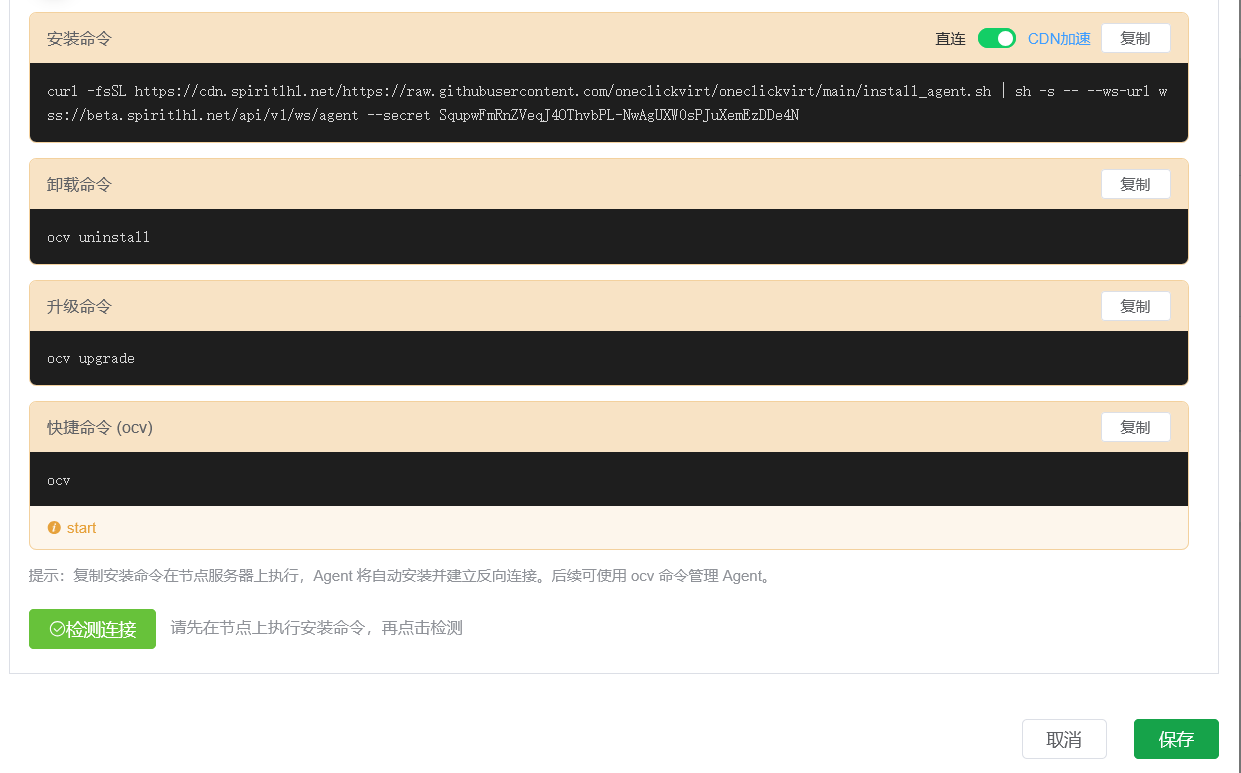
点击保存后,可以在页面中的 连接配置 区域看到生成安装命令的按钮。
需要特别注意:
节点保存后,系统会生成并写死当前节点的
TokenToken 无法单独刷新或修改
若 Token 泄露,只能:
- 删除当前节点
- 重新新增节点
- 重新填写所有配置
因此请务必妥善保管 Token,避免泄露。
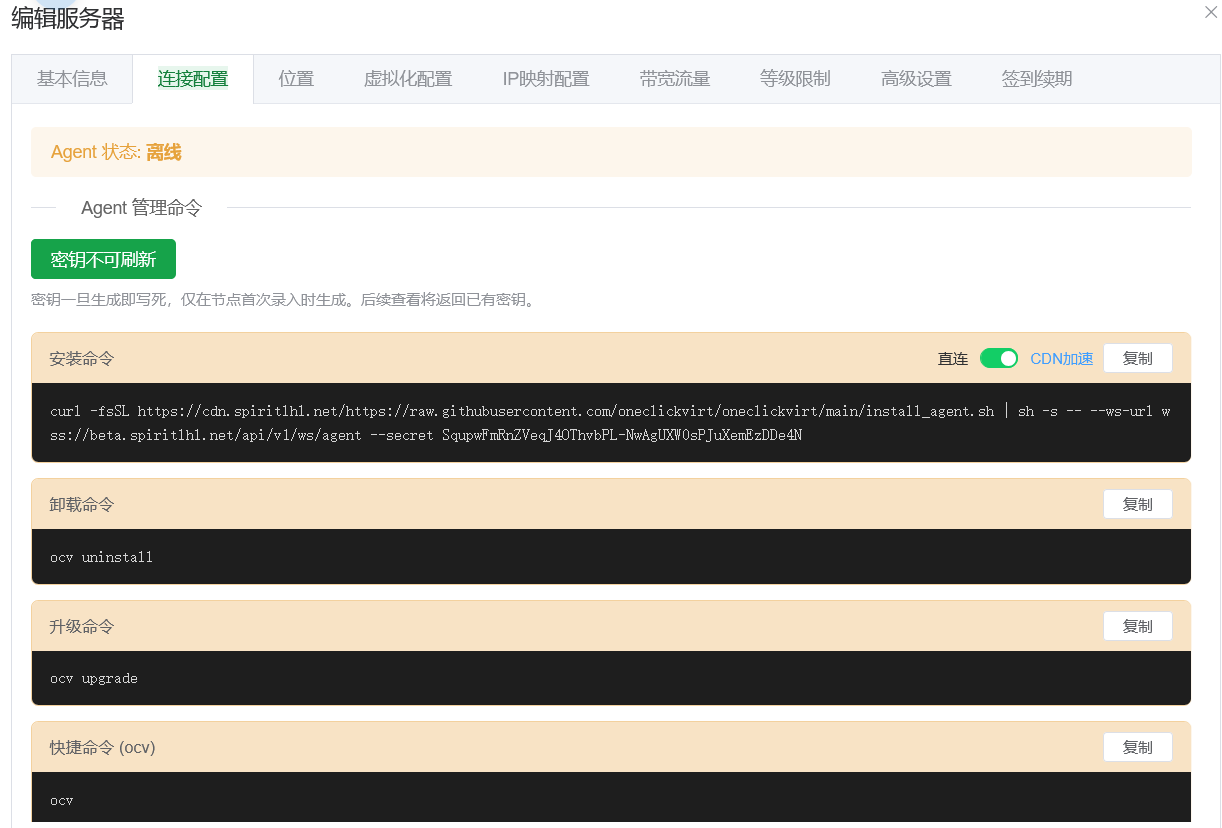
点击生成后,会得到对应的安装命令。
直接复制该命令,并在目标节点服务器上执行即可完成 Agent 安装与接入。
安装完成后,可以在当前页面下方点击 检测 按钮验证连接状态。
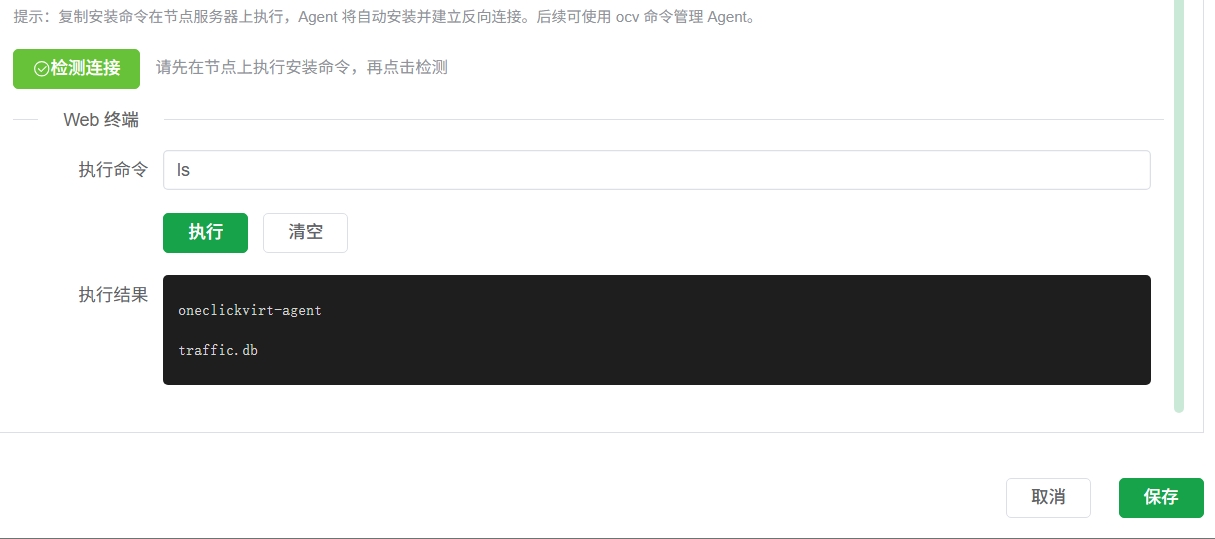
当检测成功后,后续的大部分配置流程与标准模式基本一致,无需额外特殊操作。
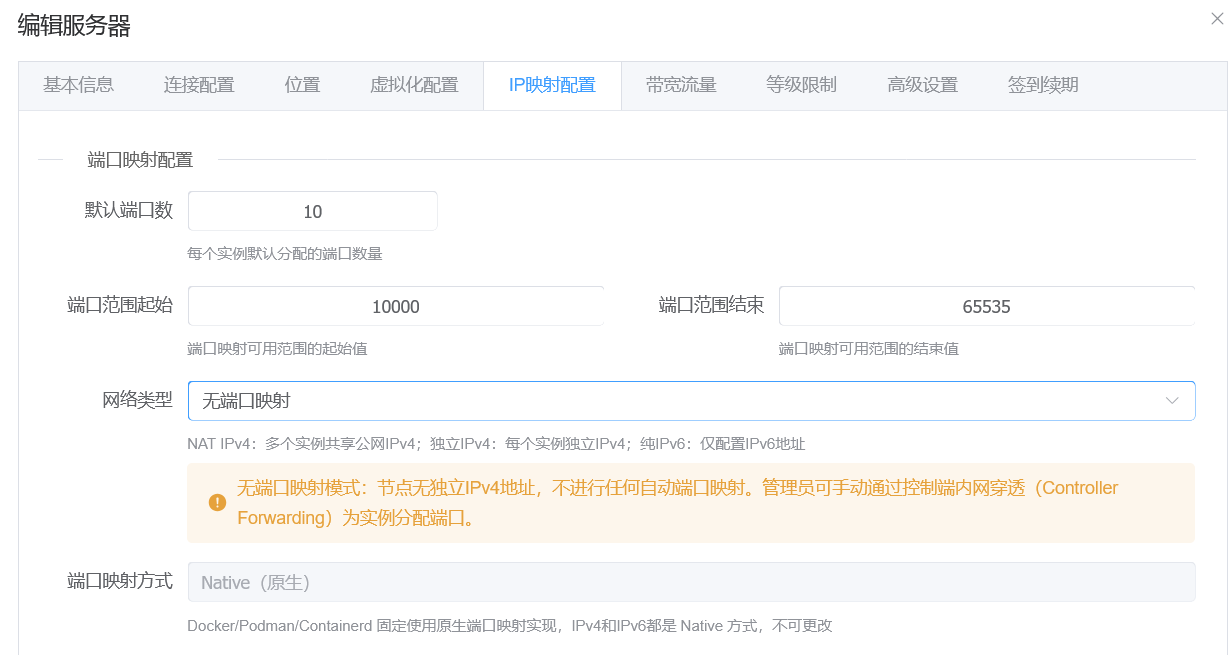
仅在 网络模式 配置部分,本地节点需要特别注意:
请务必选择无端口映射
这样后续即可通过管理员后台的端口管理
页面,手动执行添加端口
将节点内部端口映射(内网穿透)到主控服务器的 IPv4 地址上供外部访问。
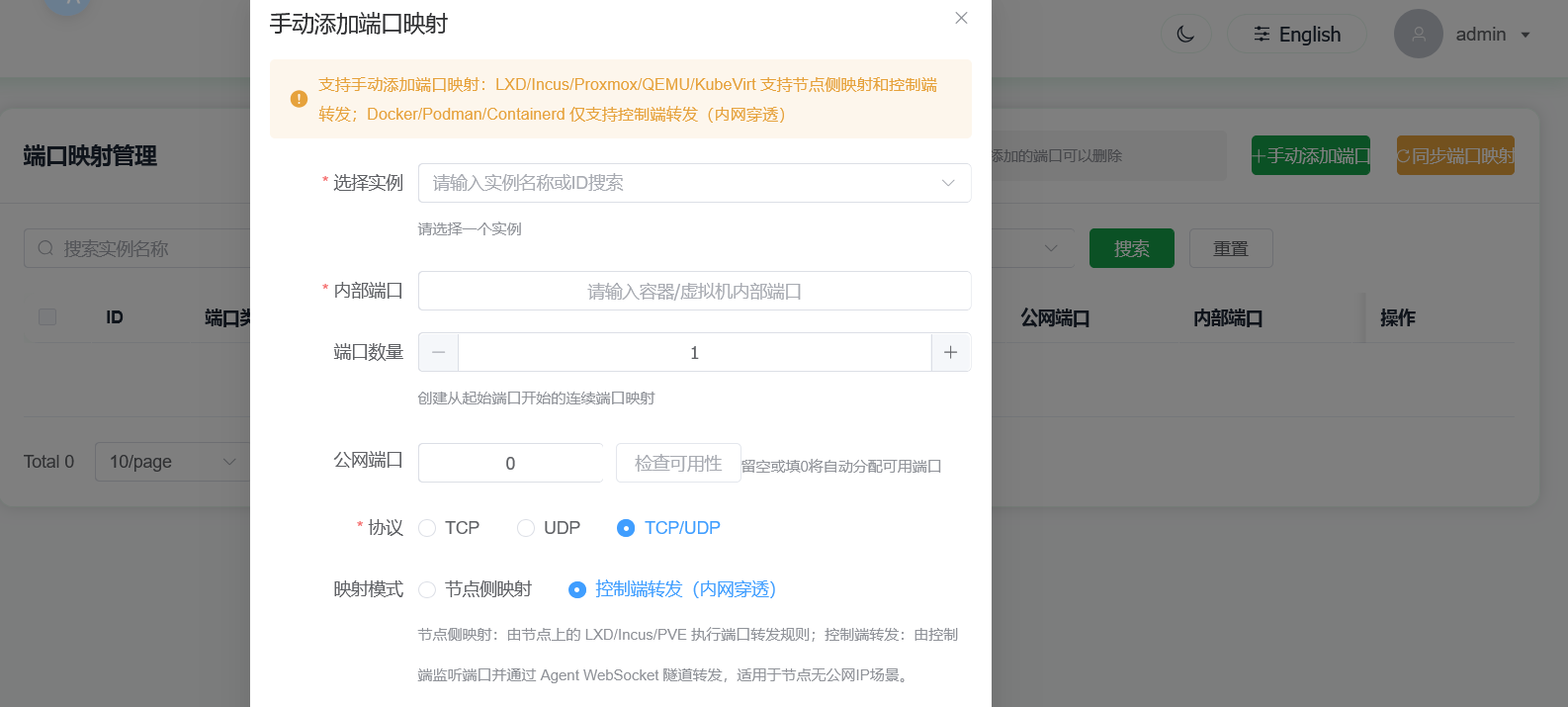
在手动添加端口映射时,请选择:
控制端转发(内网穿透)
对于非必填项,可以直接留空,系统会自动筛选并分配主控服务器可用端口。
控制端转发使用 TCP 隧道,每条映射仅支持一个 TCP 端口。需要暴露多个端口时,请分别创建多条映射。
主控部署要求
由于内网穿透功能需要主控具备对宿主机网络与防火墙的控制能力,因此主控必须满足以下条件
使用二者之一:
脚本部署裸机编译部署
部署于:
- 拥有独立公网 IPv4 地址的 Linux 服务器
必须具备:
Root 权限
不支持以下部署方式
DockerDocker Compose- 非 Linux 系统
否则将无法正常使用内网穿透相关功能。
内网穿透功能说明
内穿端口 功能:
仅支持 Agent 模式纳管的节点
通过:
WS/WSS- WebSocket 隧道转发实现
因此在配置反向代理时,请务必确保:
已正确配置协议转发支持:
WSWSS
否则内网穿透将无法正常工作。
安全建议
如果被纳管的节点存在:
- 防探测
- 防封禁
- 隧道保密
等需求,强烈建议:
- 为主控绑定域名
- 配置 HTTPS
- 纳管节点时使用
WSS 协议而不要使用WS 协议
这样可以有效降低隧道被识别、探测或封禁的风险。
版本更新说明
当主控版本更新后,请务必同步更新节点侧 Agent。
更新过程中使用source为controller,将直接从主控特定路径下载脚本和agent所需的文件。
使用LXD/INCUS开设共享GPU设备的容器
对于需要共享GPU设备的节点,务必确保纳管节点前节点本身已安装号对应的显卡驱动,且该显卡本身的命令执行无误,比如
nvidia-smi要确保显示类似
root@a12-ThinkStation-P620:/root/sharefile# nvidia-smi
Sat May 16 20:23:07 2026
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.171.04 Driver Version: 535.171.04 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:61:00.0 Off | Off |
| 30% 42C P0 83W / 300W | 0MiB / 49140MiB | 1% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+只有宿主机安装好了驱动才能进行容器化共享GPU资源。
然后需要通过本教程中的Incus/Lxd的教程,进行好本地环境的安装,安装完毕后,通过主控的agent模式纳管完毕且执行健康检测无误后,才进行后续的操作。
推荐开启节点仅兑换码兑换模式,通过管理员的兑换码页面选择GPU设备创建容器。
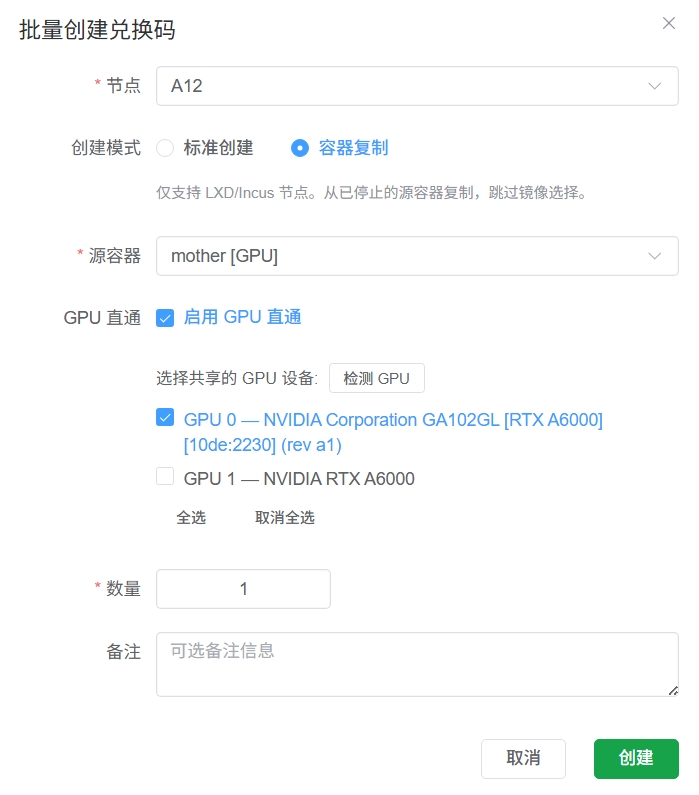
创建成功后,切换为管理员的普通用户视图兑换掉,然后回到管理员视图,去端口管理页面进行容器的端口内穿,方便直接通过web的ssh进行连接配置。
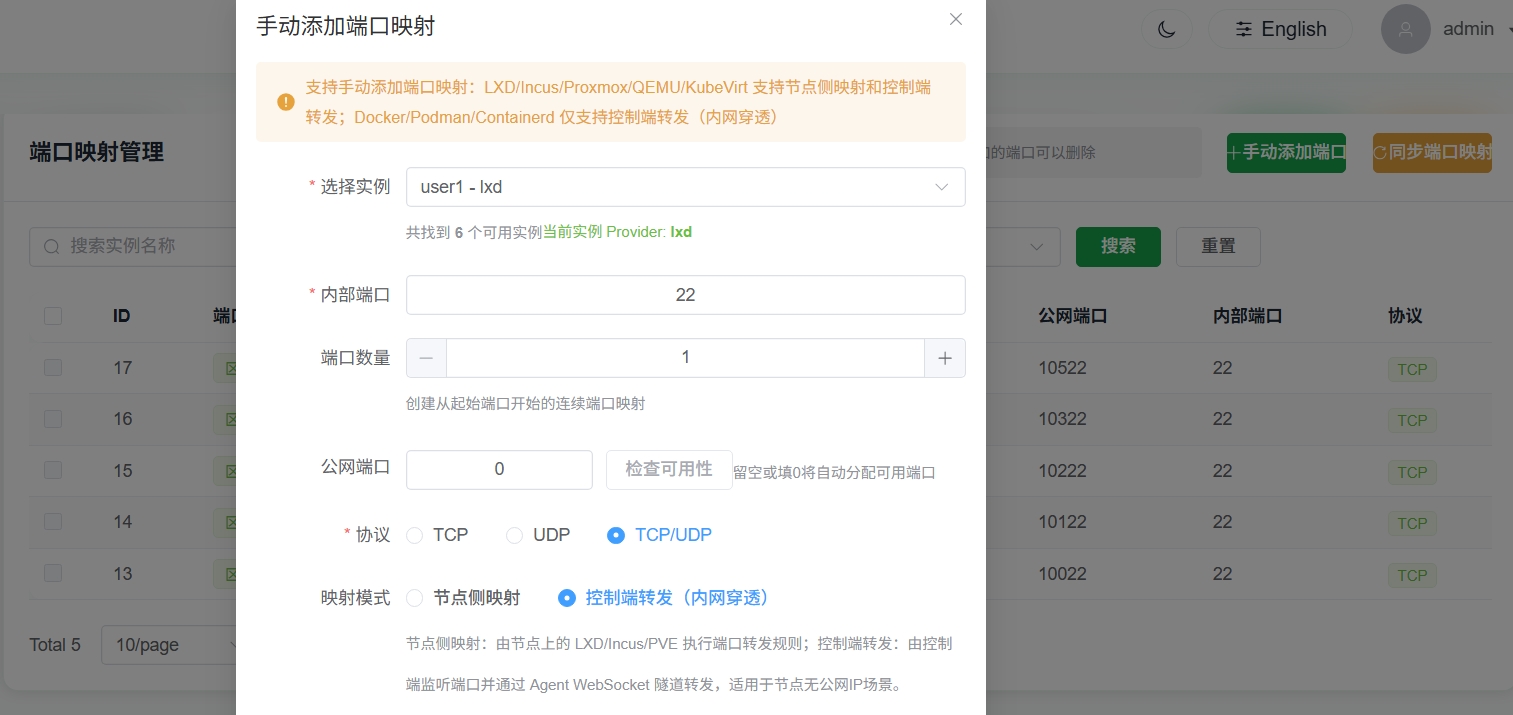
添加成功后,可以直接通过web的ssh进行连接操控本地的这个新容器了。
进入容器后,需要安装对应的和外部宿主机一样的驱动版本,只不过这次安装的时候,要确保不要加载进入内核,添加命令参数--no-kernel-module。
具体如何找驱动安装驱动,详见 https://www.spiritysdx.top/20240513/#容器内安装gpu驱动 如何进行的驱动安装。
安装完毕后,容器内也可以执行nvidia-smi得到输出,证明GPU已共享使用了。
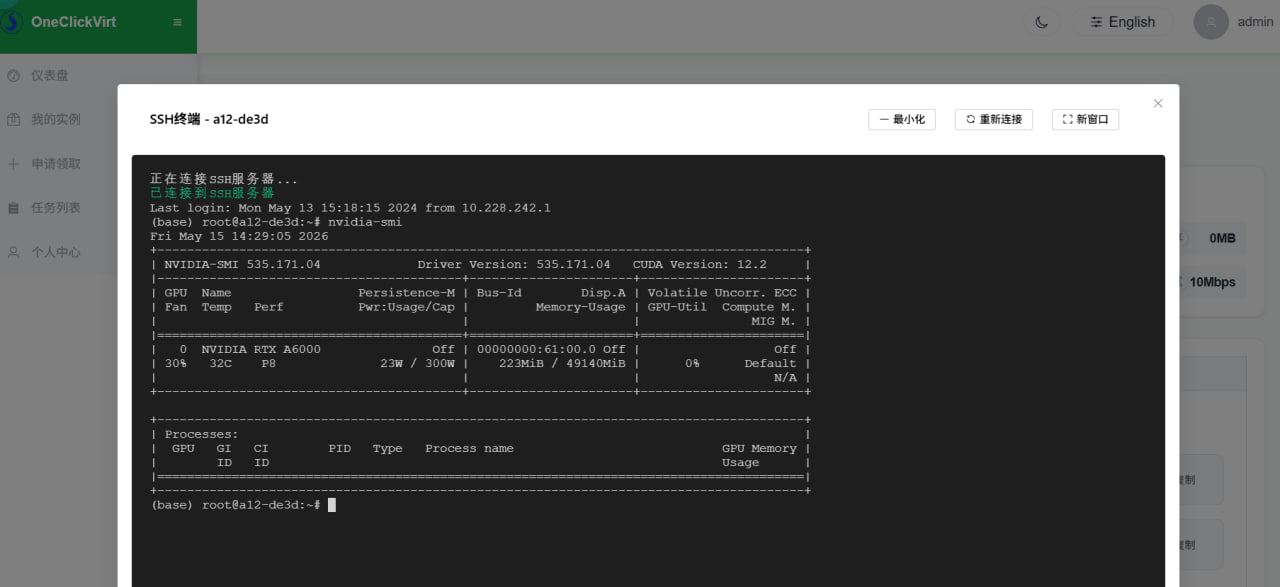
那此时就可以停止这个容器,以此为母本,使用兑换码的批量开设容器的复制模式,设置此容器为源容器进行复制开设新容器了。